Capping off my first year of Data Science was a head first immersion into a cross-functional, non-profit tech project. An exploration of what the job was going to look like without the guidance of planned lectures and graded homework assignments. This was not a test.
For some beginning clarifications, I was a member on a team of 5 Data Scientists and 5 Web Developers. Together we were given a list of directives and a deadline. No matter our comfort level, no matter our experience, the stakeholders called and we had to answer. Welcome to Story Squad.
Story Squad is a non-profit company started by CEO and stakeholder Graig Peterson. A former teacher, Graig has observed the inevitable changes in the social dilemmas of the young generations. Screen time has consumed children more than they consume it. Minimization of creative opportunities lessen the indulgence and expression of a child’s mind. These roadblocks are withholding potential. How do we fix this?
• • •
| Human connection through creative expression. |
• • •
The Game is Afoot
Debating this problem could keep some philosophers busy for hours. Graig, however, decided to eagerly fight fire with fire by creating an app to reverse the negative effects inflicted on these children by devilish digital masterminds. Currently, this solution is just under a year into development and has already been built up by strong individuals showcasing their talents. In attempts to fill these shoes, I became a part of this legacy to iterate and innovate.
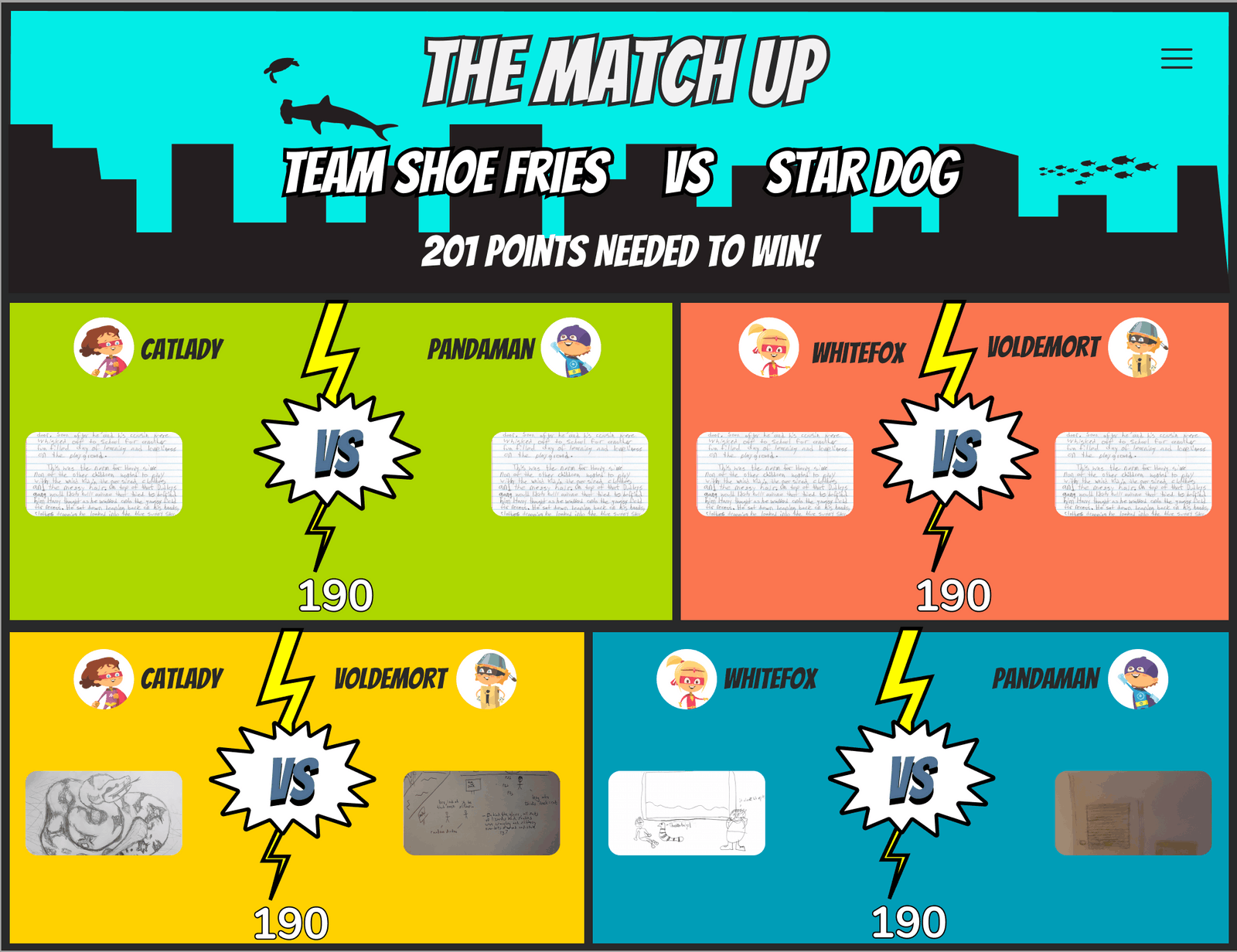
This app is designed to redirect focus off of screens and on to hands-on experiences. Users (children) will read a prompt and be asked to write a side quest and, subsequently, create a respective depiction of what they wrote. After multiple users have made their submissions, they are pitted against each other in a ‘battle’ of point allocation (shown on the left). Throughout this process kids are able to send and receive both points and feedback on their opponents’ stories and illustrations. At first glance, this may seem like a pen and paper Call of Duty. However, this app is a means to an end. As it’s already been discussed, the hand writing assignments take the ‘screen’ out of screen time and the point share segment has a purpose as well.
Piecing together the conceptual underpinnings of this invention was a task on its own but I was given my orders and it was time to fulfill them. Specifically, my research and development began with the assumption of a heavy codebase. However, this sea of code quickly became the least of my concerns when my team and I discovered what was really in store for us. Below the beautiful surface of this app, the Data Science back end turns its gears like a V-12 engine. Mechanics ranging from calculating scores for user submissions to using clustering algorithms to group opponents together into teams of 4 for the signature battle phase make this app the masterpiece that it is. A crucial element to many of these tasks, however, is the transcription of a child’s side quest submission image to a string useable by the computer. That’s what my team and I would be exploring.

The implementation at the time was the clever use of Google’s Cloud Vision API. Similar to Amazon Rekognition or Textract, these paid resources are OCR (Optical Character Recognition) engines that can fulfill such a complex assignment. The stakeholder’s goal was to replace these costly endpoints with something open-source. We were introduced to a new OCR engine called Tesseract and it seemed like the cards were stacked against us:
- Start from scratch using an open-source product to transcribe children’s handwriting (something that has barely been explored in the tech industry)
- Compete with Google and Amazon releases to procure accurate and relevant results without the cost
- Given a one month window of opportunity to integrate our findings
With the prospect of working through, to us, unknown technologies in order to provide industry-revolutionizing results was both exciting and absolutely terrifying. We took a collective deep breath and left-clicked.
• • •
Tedious Tesseract
My team and I quickly discovered that Tesseract has fairly complex and sporadic documentation, so my work began with extreme note-taking. My goal was to cut down Tesseract-related intimidation and onboarding time for future Story Squad programmers. I began documenting anything I could to both accomplish my goal and understand what I was looking at. Our group slowly, but surely, grew to be on the same page through this team-bonding exercise. After filling in the gaps, it was free game to start coding things up.
Still in the time-saving mindset, I knew that trying to automate as many processes as I could would help in the development of this project. Before my fingers hit the keyboard, however, I found that Tesseract mainly runs on shell scripts. As this would be, essentially, a new programming language, I spent some time learning and researching. In the end, my contributions were mainly focused around the Tesseract training process while my colleagues were focusing on prepping input data and handling outputs.
Not much documentation was provided for training Tesseract with image data and I knew this was going to be an issue. Thus, in order to truly understand how I could maximize training efficiency, I spent a couple days reading through various Tesseract C++ and shell scripts (one of which shown on the left). Trust me, I had the same headache you are when I first looked at this code too. This exploration provided me with the foundations I needed to start my custom training process. I simply began a new shell script that would create all the training files required by Tesseract (using the prepared input data from my teammates) and use them to train the model all at once.
• • •
Throughout this project, each day consisted of a 2-to-1 ratio of studying to code. Fortunately, four weeks was enough time to ship a couple features and a handful of documentation that would surely please the stakeholders. I sent forward two sources of documentation: one being for the next group of Story Squad programmers and the other a quick reference guide for anyone to be able to start a project with Tesseract. As far as code is concerned, my largest contribution was the training script mentioned above. Below is a look into its functionality and purpose.
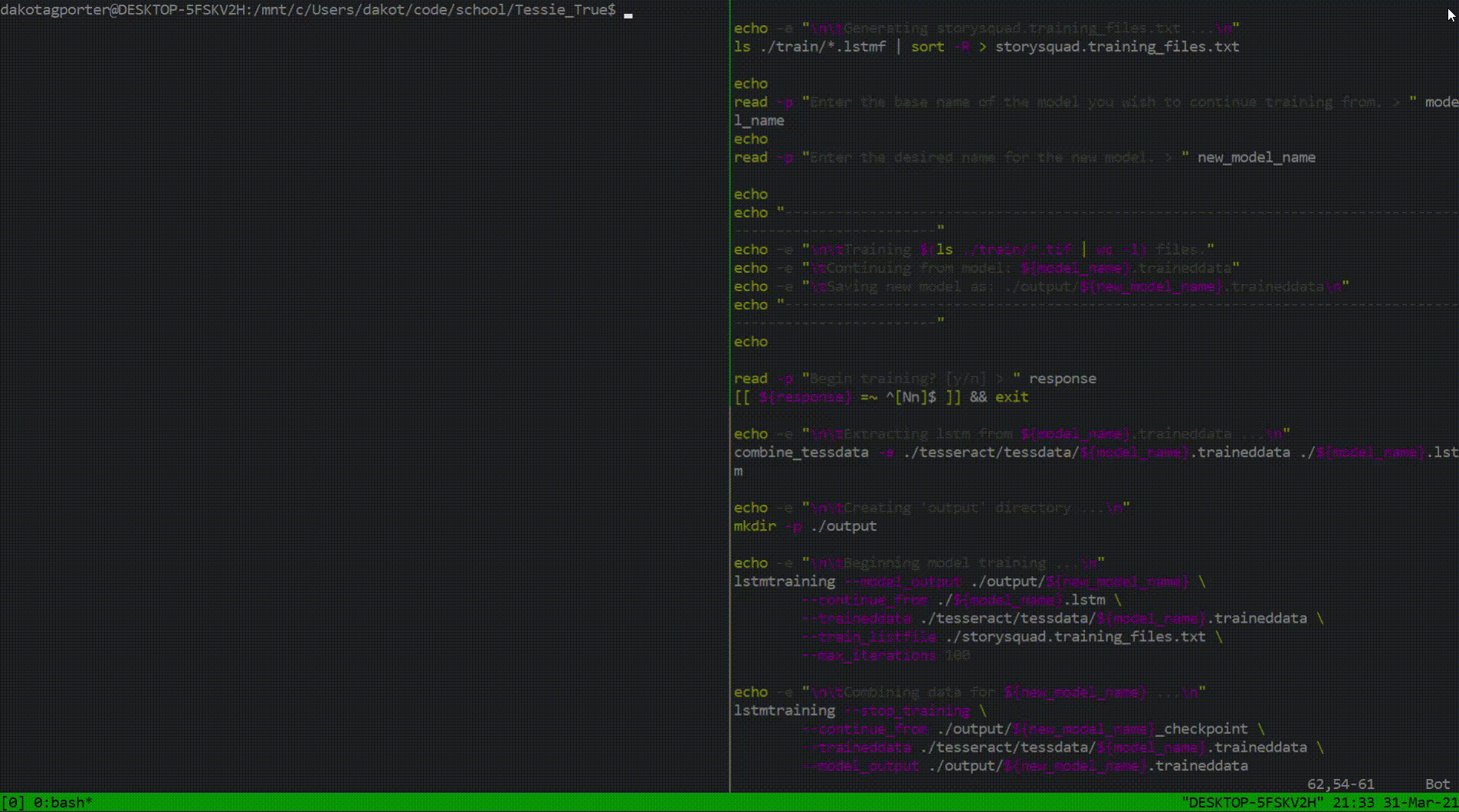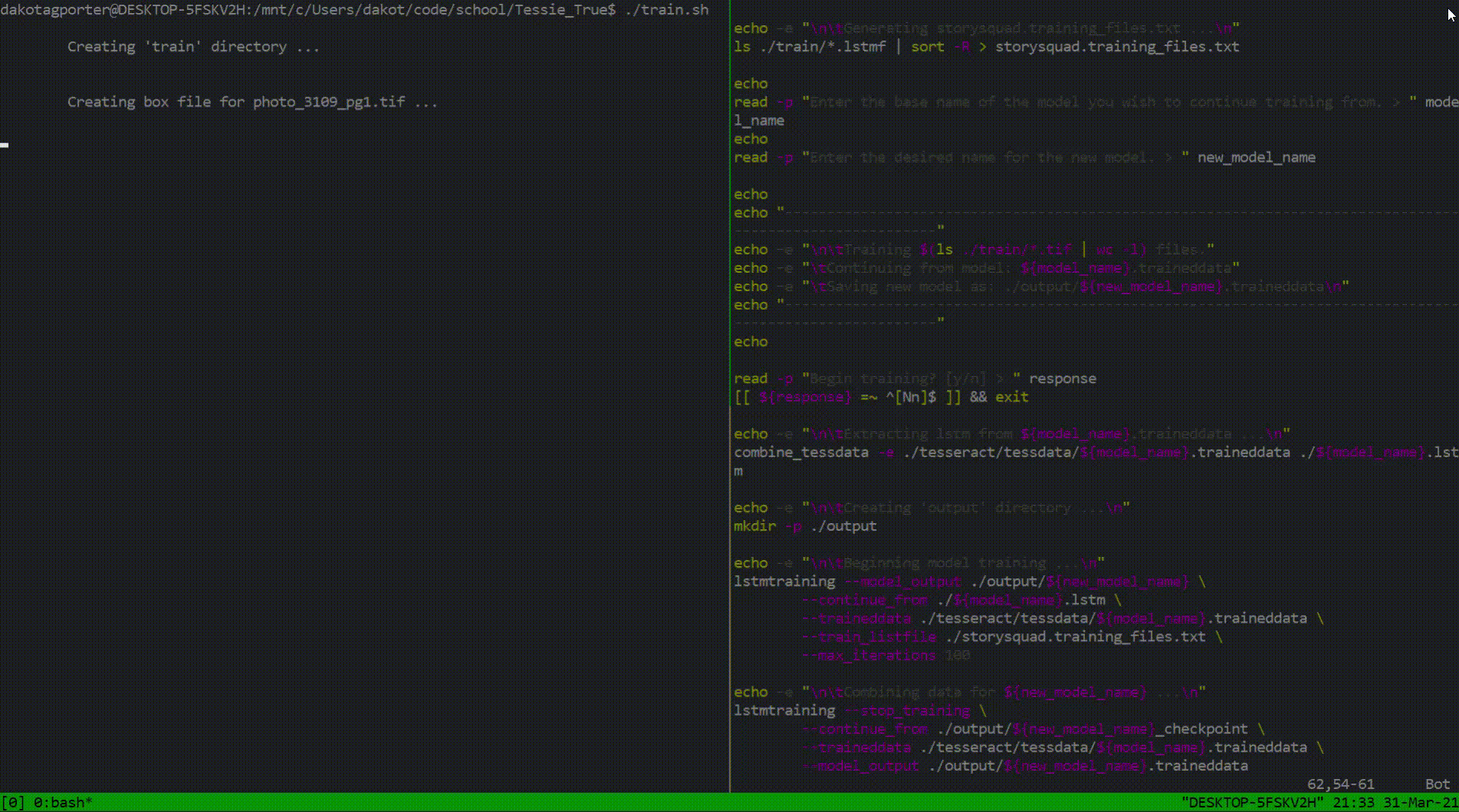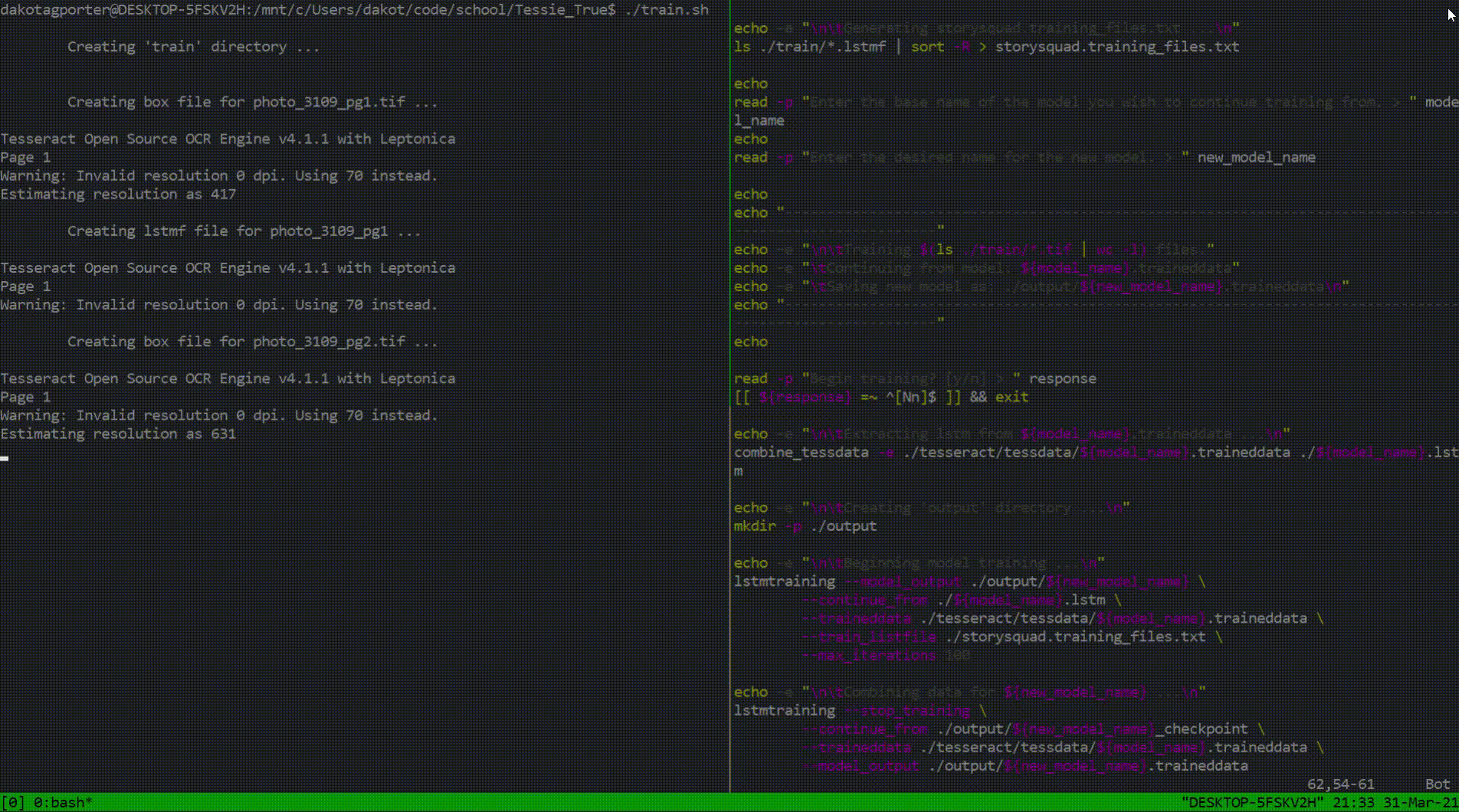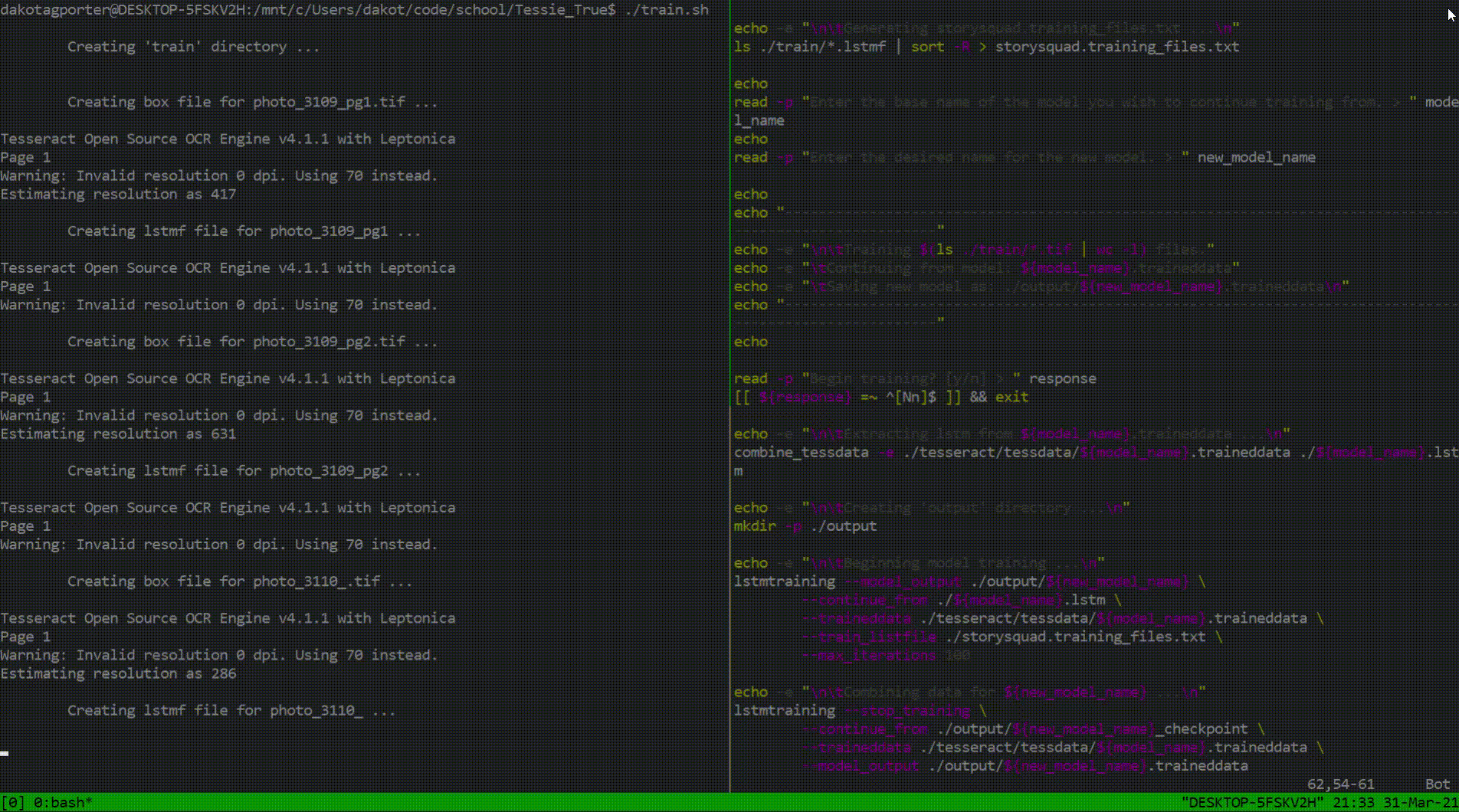
This script was intended to be a renewable resource. I incorporated Tesseract features in conjunction with shell code that would allow this program to be as generalized as possible. Training is not an easy feat when it comes to Tesseract, so efficiency was key. Now, future Tesseract explorers can spend more time zeroing in on image preprocessing techniques rather than stressing about training idiosyncrasies.
• • •
What Now?
The deadline crept up quickly after the delivery of this feature. However, knowing that our processes had been well documented and mostly automated, we were confident in our contributions as a team for the future of this project. The desired outcome of Tesseract implementation would be to focus on making slight improvements and adjustments to our preprocessing-training pipeline. Additionally, tracking metrics such as word counts or using spell check to correct submissions to improve NLP processes that happen during scoring are a couple of features that I could see implemented in the near future. This was made very clear through our documentation and we felt confident that future Story Squad programmers could see this through to the end. Perfecting training will be a major step in the development of this app. This was not our only hope however.
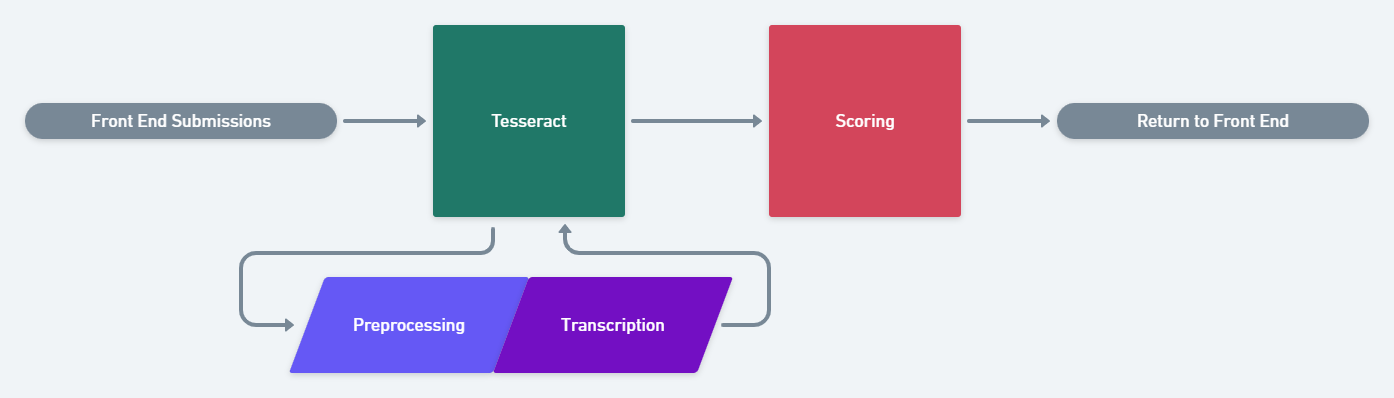
I wanted to ensure that a scaffolding was integrated into the current back end (shown above) to, yet again, improve efficiency once the final Tesseract model has been trained. This scaffolding would be a mixture of highlighting and refactoring various sections of code so that very minimal work would take place to, ultimately, make the switch from Google Vision to Tesseract. It’s possible that these newcomers will have to indulge in some refactoring of their own due Tesseract’s specificity. Hopefully, however, we have given them the tools to fine tune and perfect a model worthy of transcribing unforgiving handwriting.
• • •
I had a very solid team and it was a disappointment to leave them. We kept up constant communication and we filled in the gaps of each others progress where we needed it. My team was very happy and appreciative of my passion for halving onboarding time and attempting to push forward the ground truth (no pun intended) of what Tesseract is and how to tame it. I know in my mind, however, this was a team effort. I am extremely grateful for this project as it added many new technical, as well as soft, skills to my repertoire. I have not dealt with these technologies or environments in the past, so it was an amazing experience to get a sense of the real world. Story Squad has developed and furthered my passion for this trade and I am not looking back.
I am currently staying on the Story Squad team through an internship. Feel free to contact me for any comments or questions (I love to network)! Additionally, if you are interested, I have linked a couple of the resources mentioned throughout the article below, so take a look if you want to train an OCR of your own!
:: Tesseract Quick Start Documentation :: :: Story Squad :: :: Project Code ::